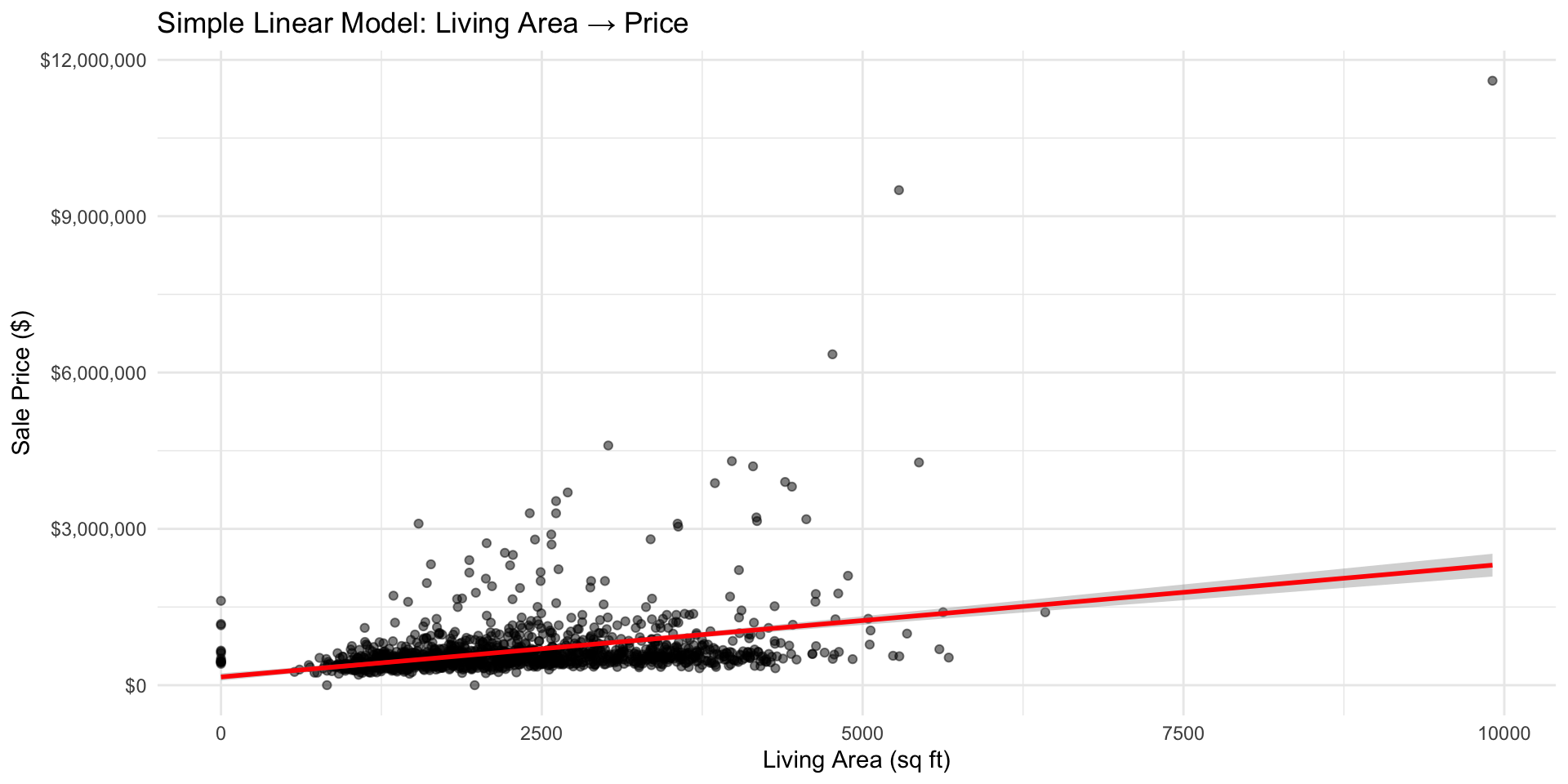
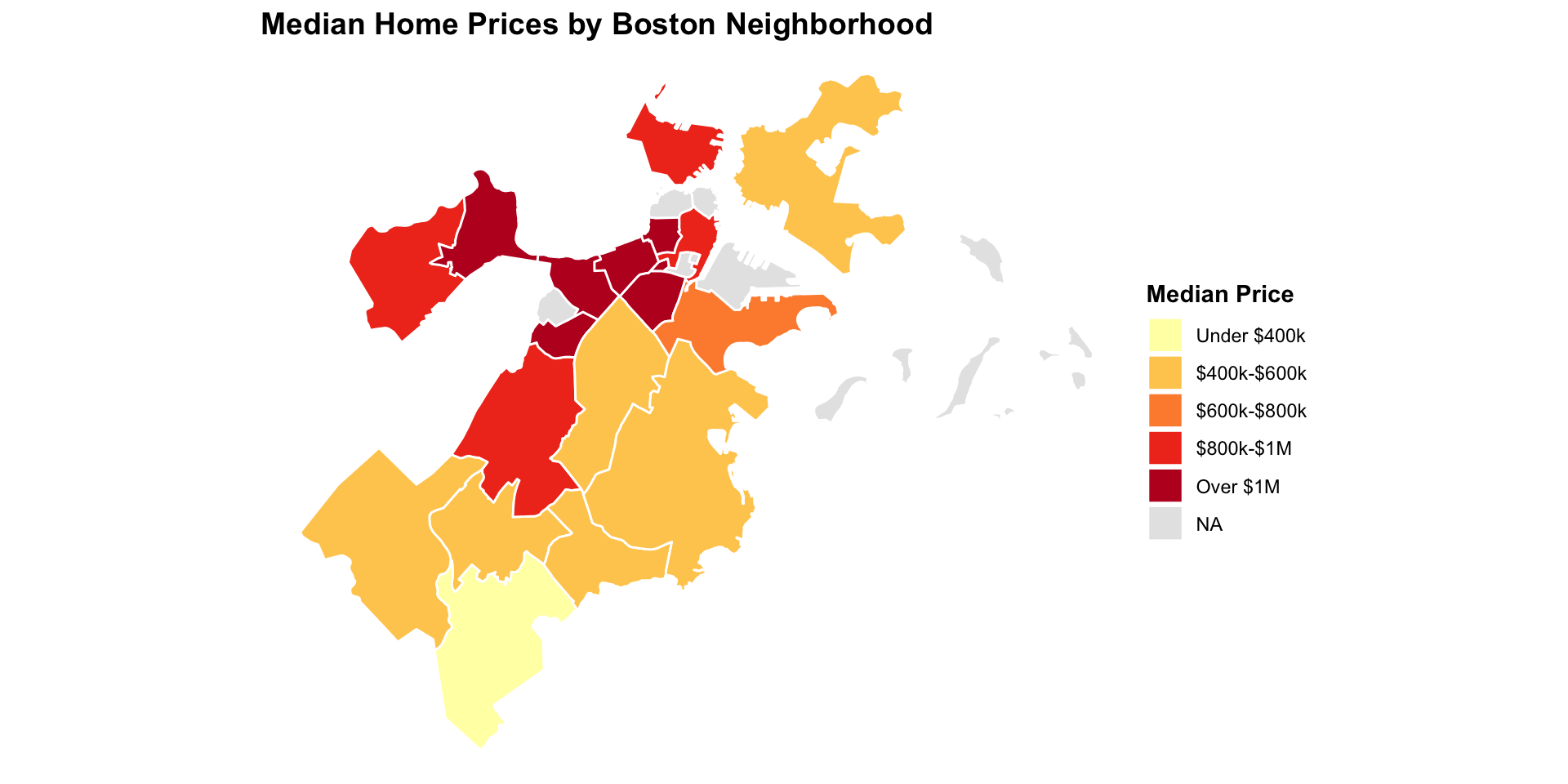
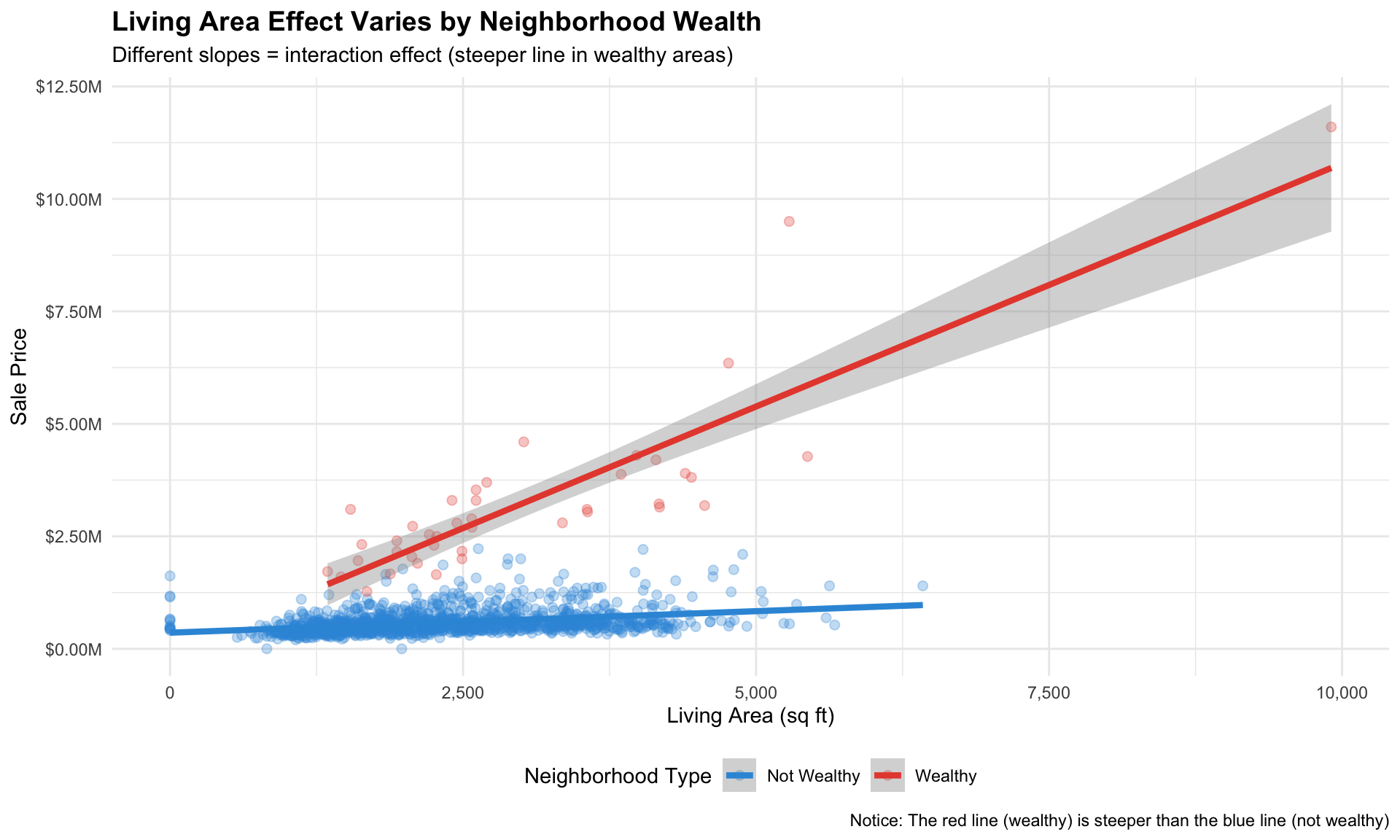
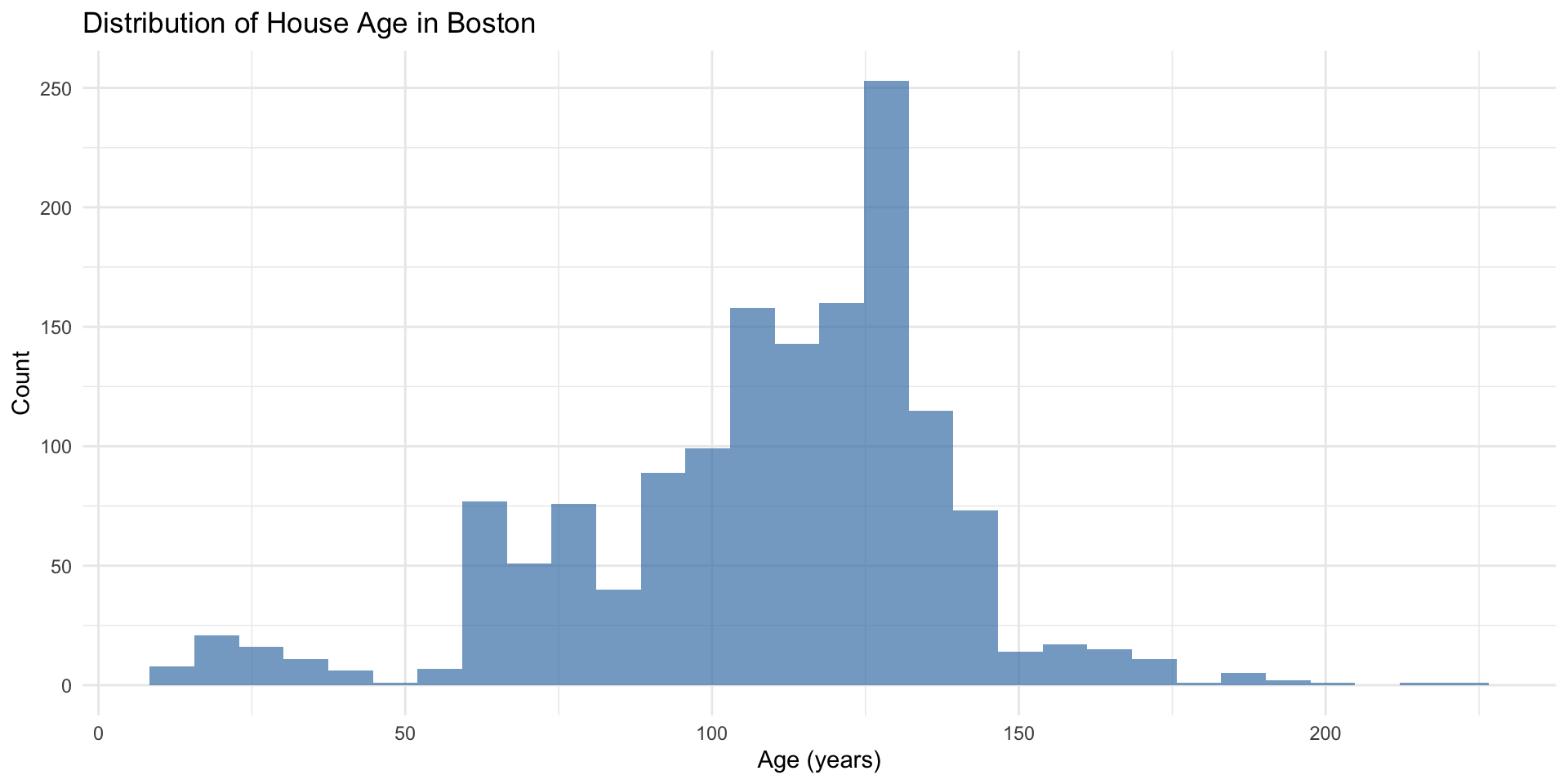
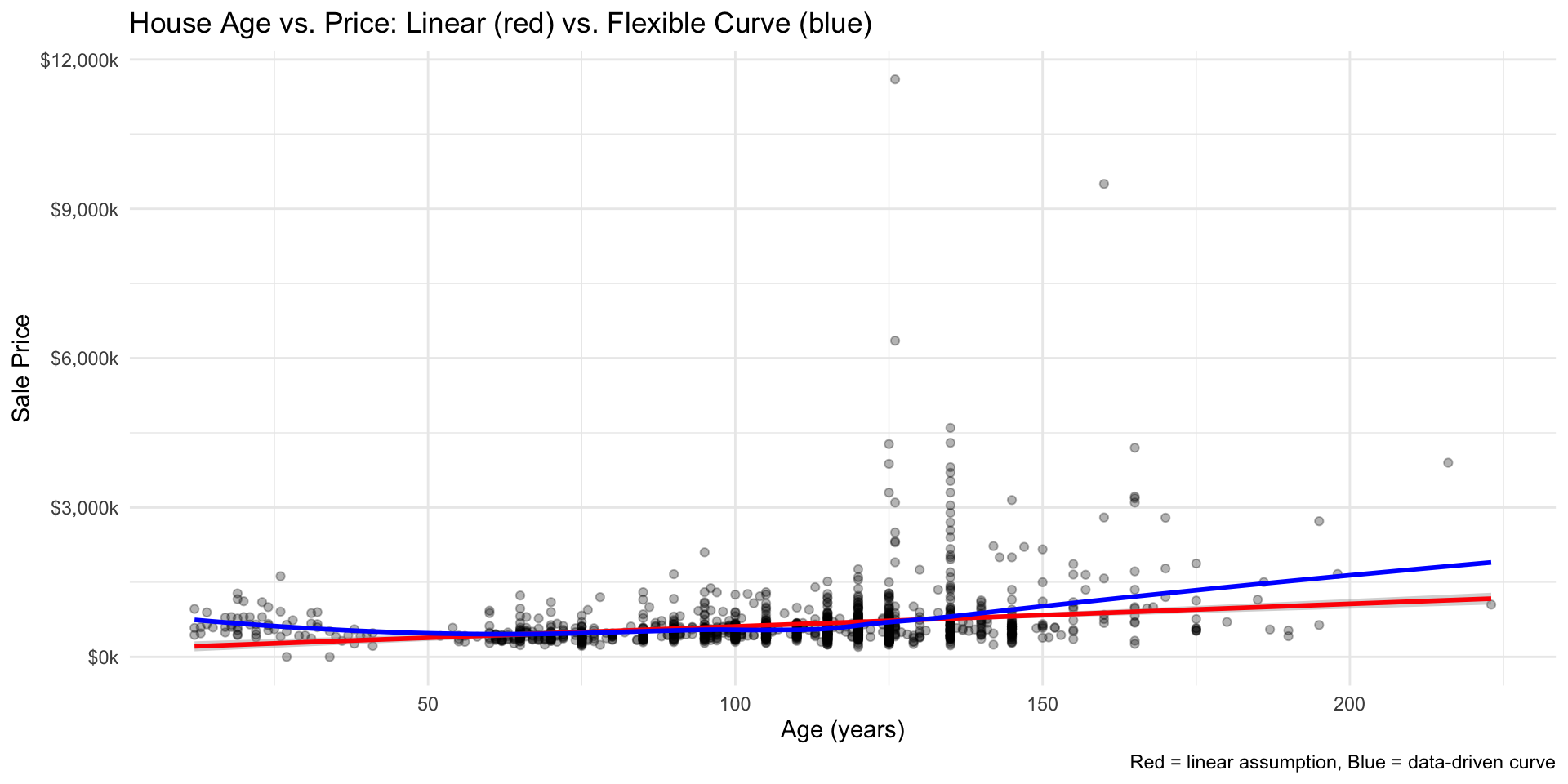
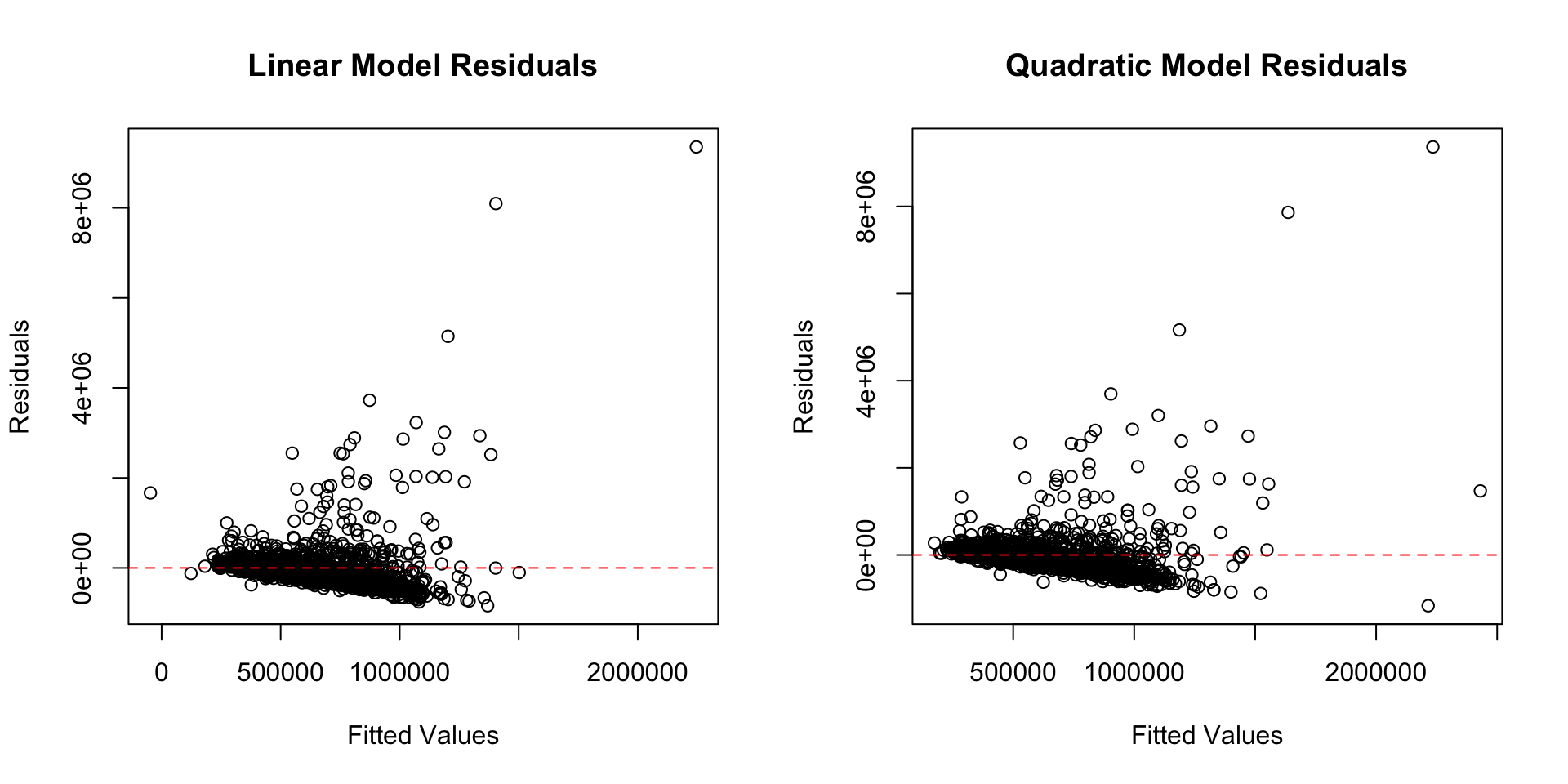
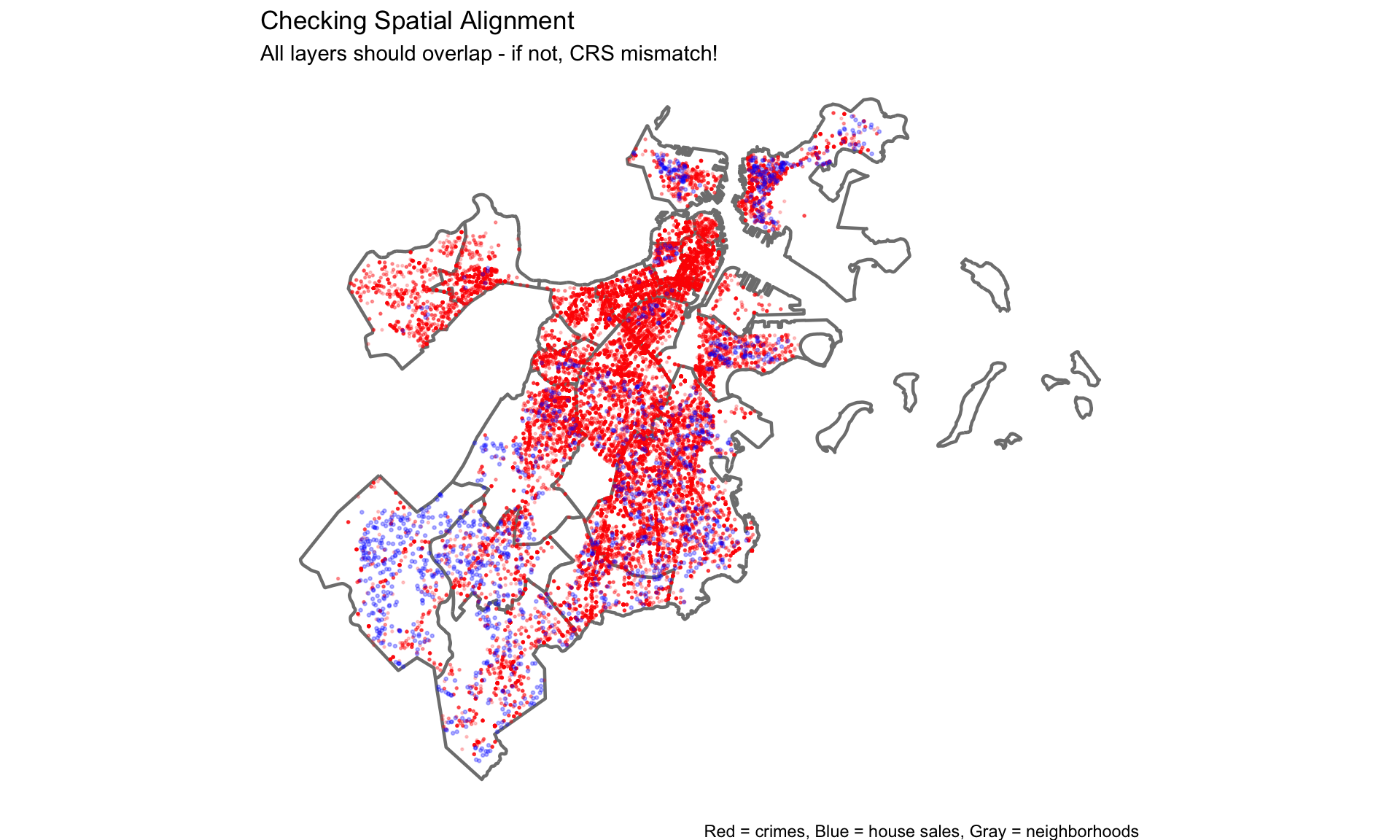
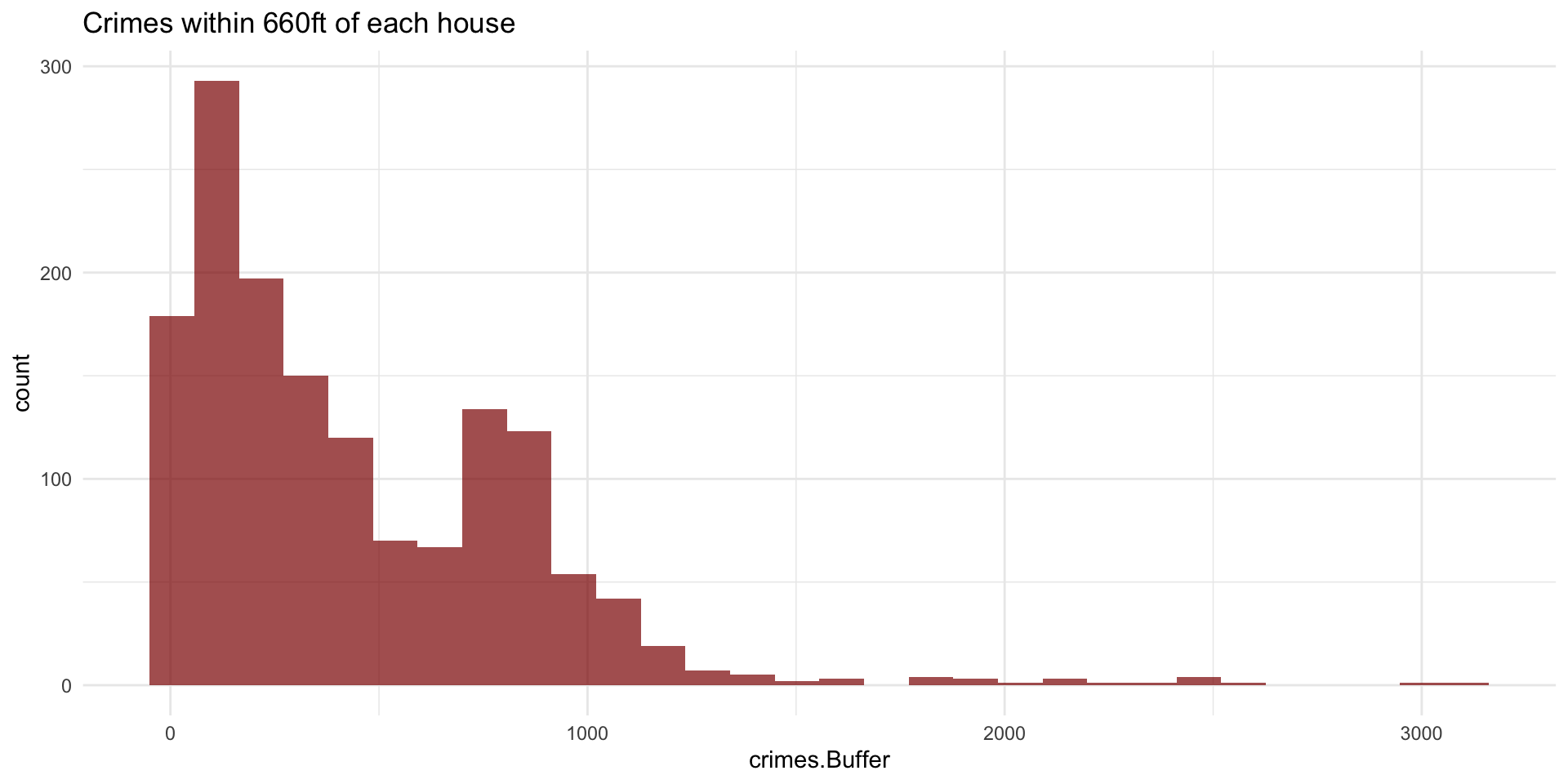
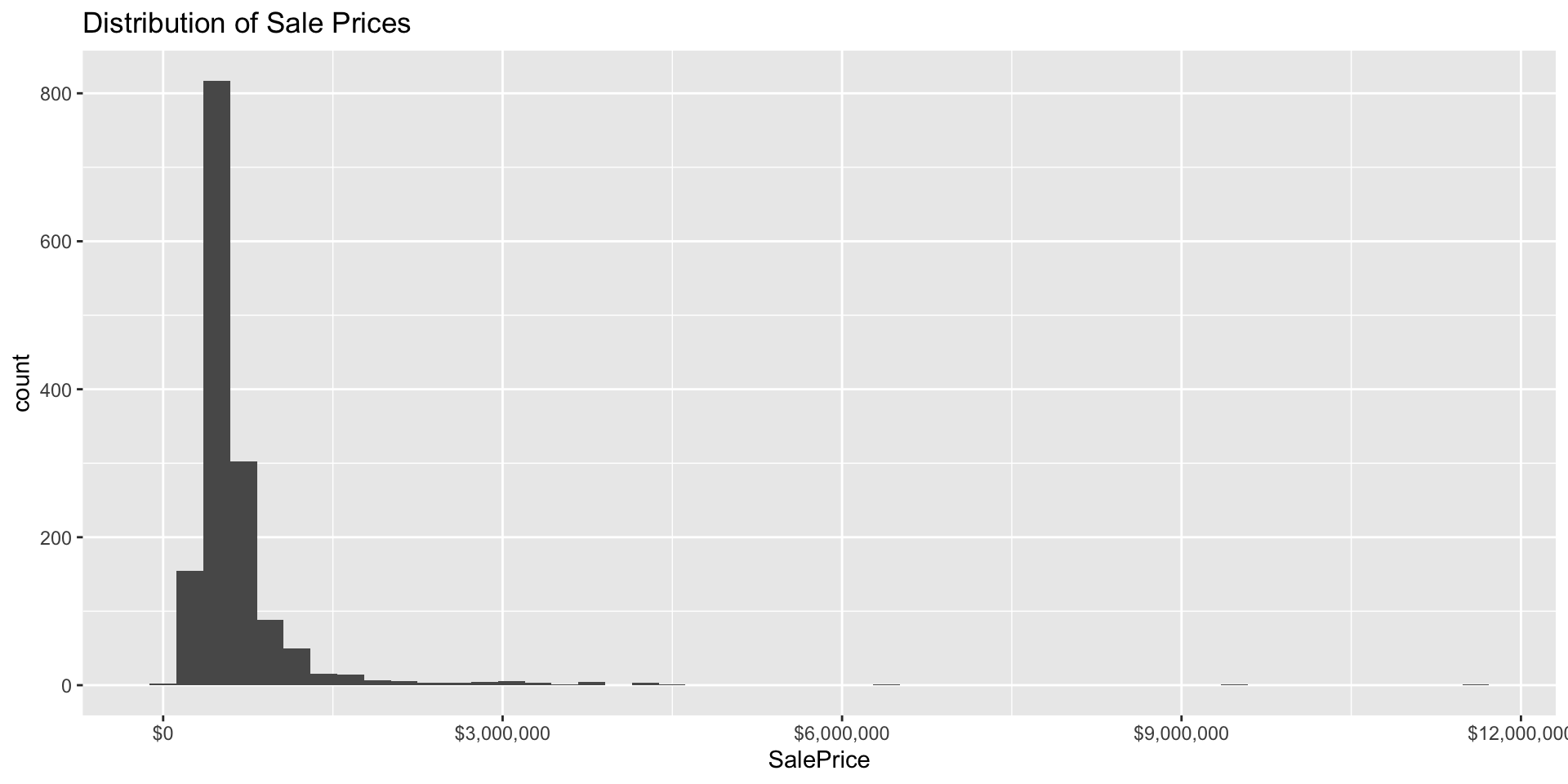
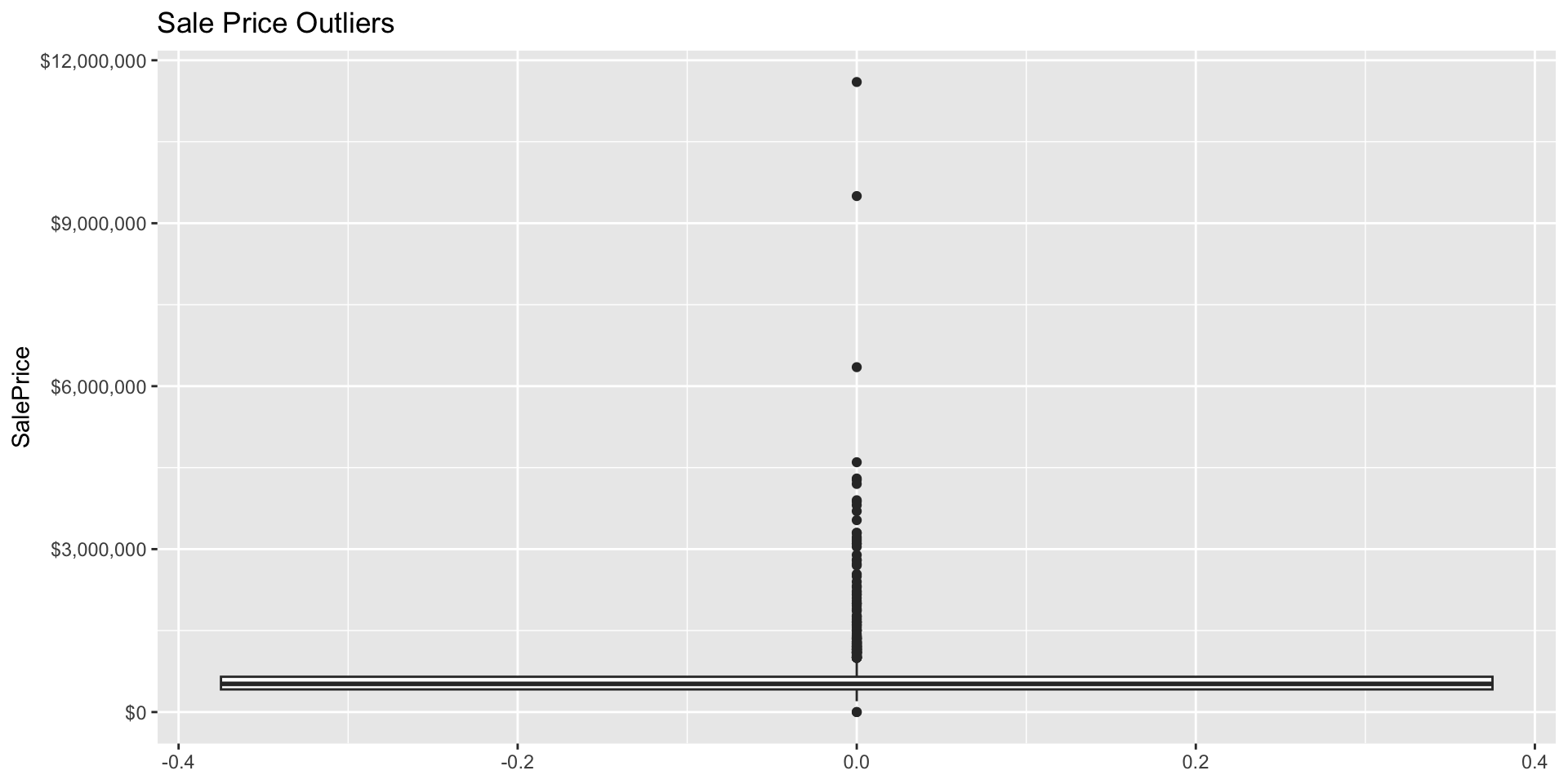
Rows: 1,485
Columns: 24
$ ...1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
$ Parcel_No <dbl> 100032000, 100058000, 100073000, 100112000, 100137000, 1001…
$ SalePrice <dbl> 450000, 600000, 450000, 670000, 260000, 355000, 665000, 355…
$ PricePerSq <dbl> 228.89, 164.34, 105.98, 291.94, 217.21, 190.96, 227.35, 120…
$ LivingArea <dbl> 1966, 3840, 4246, 2295, 1197, 1859, 2925, 2904, 892, 1916, …
$ Style <chr> "Conventional", "Semi?Det", "Decker", "Row\xa0End", "Coloni…
$ GROSS_AREA <dbl> 3111, 5603, 6010, 3482, 1785, 2198, 4341, 3892, 1658, 3318,…
$ NUM_FLOORS <dbl> 2.0, 3.0, 3.0, 3.0, 2.0, 1.5, 3.0, 3.0, 2.0, 2.0, 1.5, 2.0,…
$ R_BDRMS <dbl> 4, 8, 9, 6, 2, 3, 8, 6, 2, 2, 4, 3, 3, 3, 6, 8, 4, 4, 3, 2,…
$ R_FULL_BTH <dbl> 2, 3, 3, 3, 1, 3, 3, 3, 1, 2, 2, 3, 1, 1, 3, 3, 2, 3, 1, 2,…
$ R_HALF_BTH <dbl> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0,…
$ R_KITCH <dbl> 2, 3, 3, 3, 1, 2, 3, 3, 1, 2, 2, 3, 1, 1, 3, 3, 2, 3, 2, 2,…
$ R_AC <chr> "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N",…
$ R_FPLACE <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ LU <chr> "R2", "R3", "R3", "R3", "R1", "R2", "R3", "E", "R1", "R2", …
$ OWN_OCC <chr> "Y", "N", "Y", "N", "N", "N", "N", "N", "N", "Y", "N", "N",…
$ R_BLDG_STY <chr> "CV", "SD", "DK", "RE", "CL", "CV", "DK", "DK", "RE", "TF",…
$ R_ROOF_TYP <chr> "H", "F", "F", "F", "F", "G", "F", "F", "G", "F", "G", "F",…
$ R_EXT_FIN <chr> "M", "B", "M", "M", "P", "M", "M", "A", "A", "M", "W", "W",…
$ R_TOTAL_RM <dbl> 10, 17, 20, 14, 5, 8, 14, 14, 4, 9, 7, 7, 5, 5, 15, 14, 11,…
$ R_HEAT_TYP <chr> "W", "W", "W", "W", "E", "E", "W", "W", "W", "W", "W", "W",…
$ YR_BUILT <dbl> 1900, 1910, 1910, 1905, 1860, 1905, 1900, 1890, 1900, 1900,…
$ Latitude <dbl> 42.37963, 42.37877, 42.37940, 42.38014, 42.37967, 42.37953,…
$ Longitude <dbl> -71.03076, -71.02943, -71.02846, -71.02859, -71.02903, -71.…