exclamation_marks: Each additional ! multiplies odds of spam by 1.9793761^{24}
contains_free: Having “free” multiplies odds by 1.0033099^{20}
length: Each additional character multiplies odds by 0.2801 (shorter = more likely spam)
Making Predictions
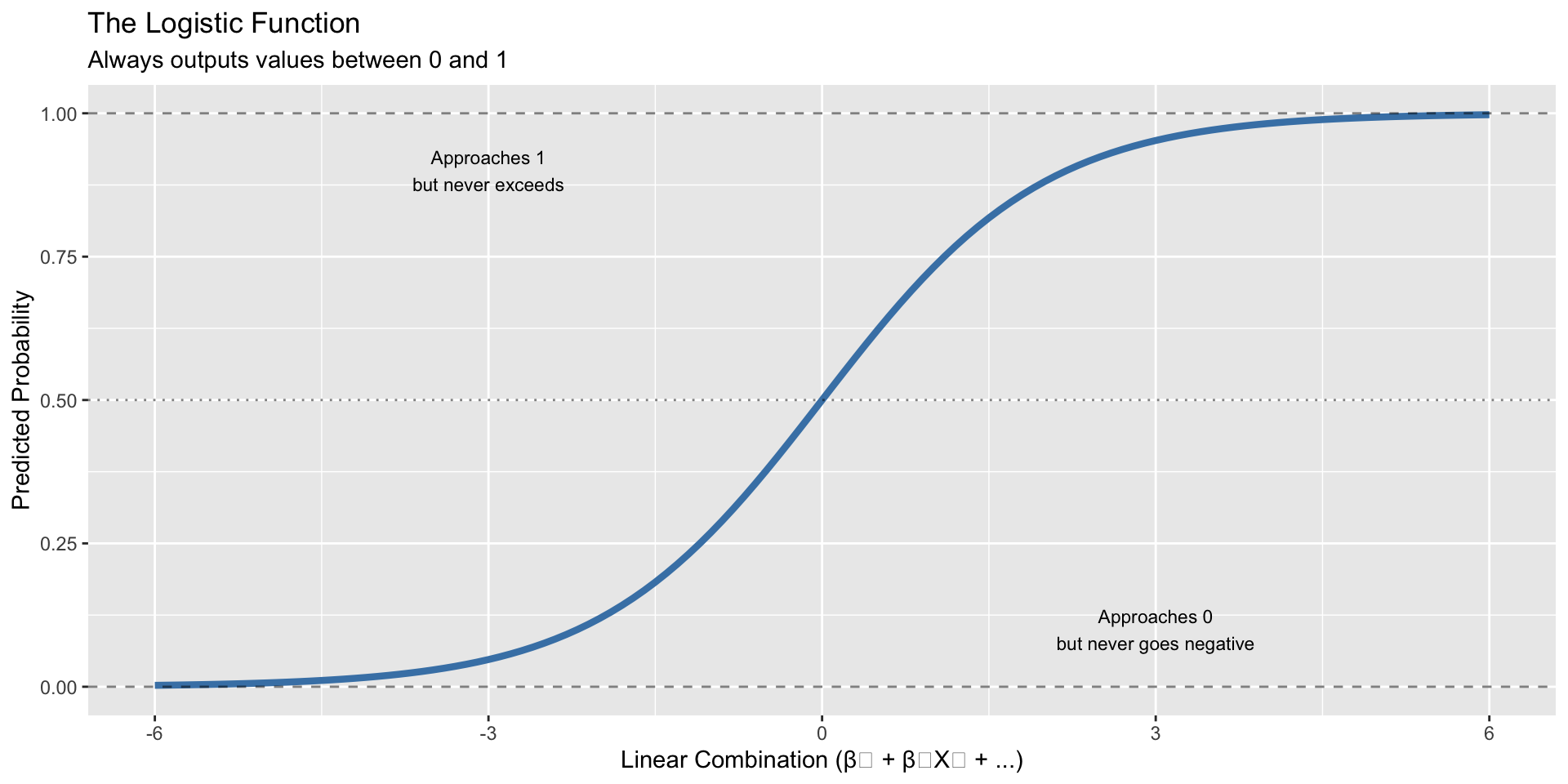
The model outputs probabilities:
# Predict probability for a new emailnew_email <-data.frame(exclamation_marks =3,contains_free =1,length =150)predicted_prob <-predict(spam_model, newdata = new_email, type ="response")cat("Predicted probability of spam:", round(predicted_prob, 3))
Predicted probability of spam: 1
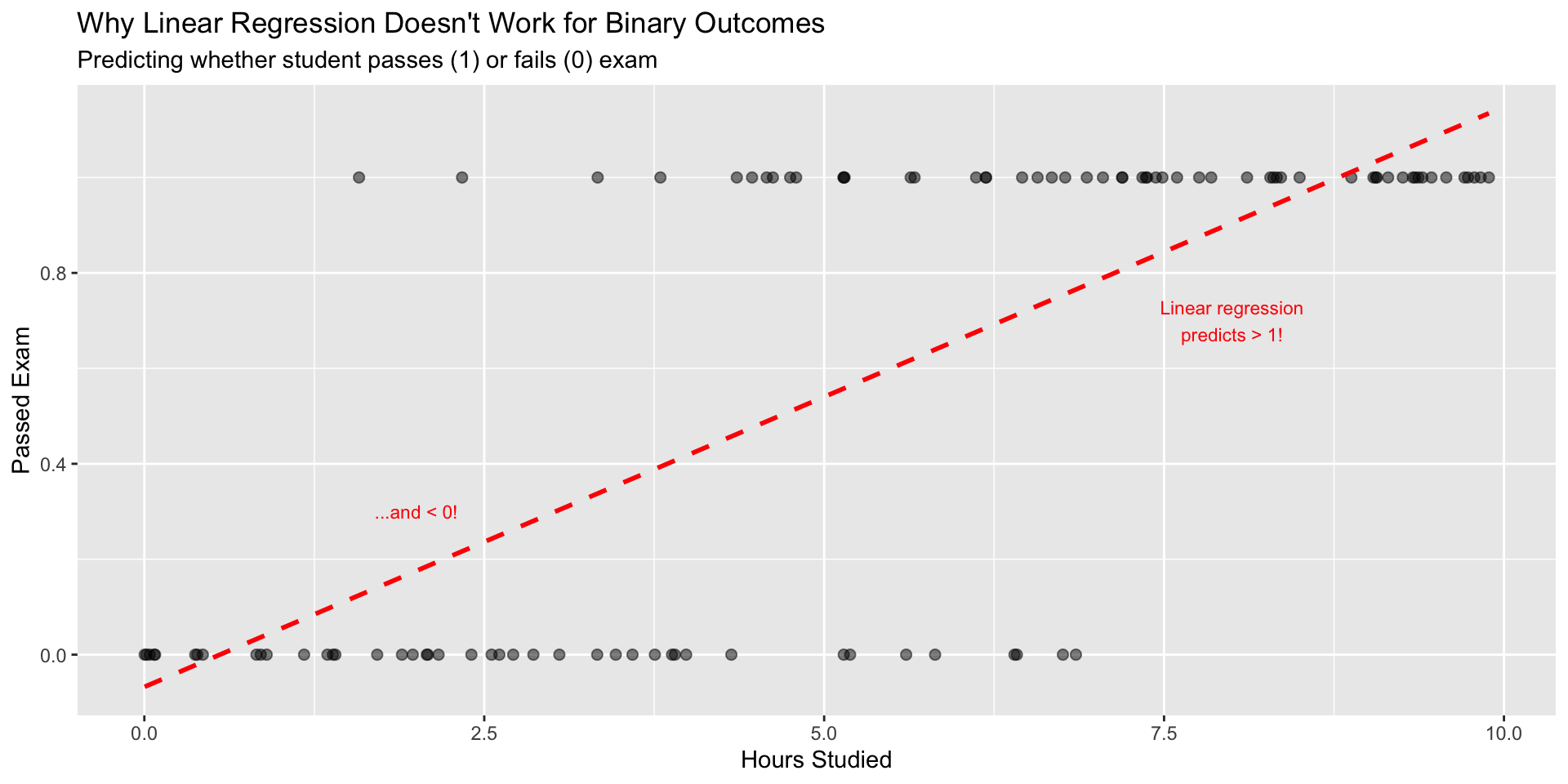
But now what?
If probability = 0.723, is this spam or not?
We need to choose a threshold (cutoff)
Threshold = 0.5 is common default, but is it the right choice?
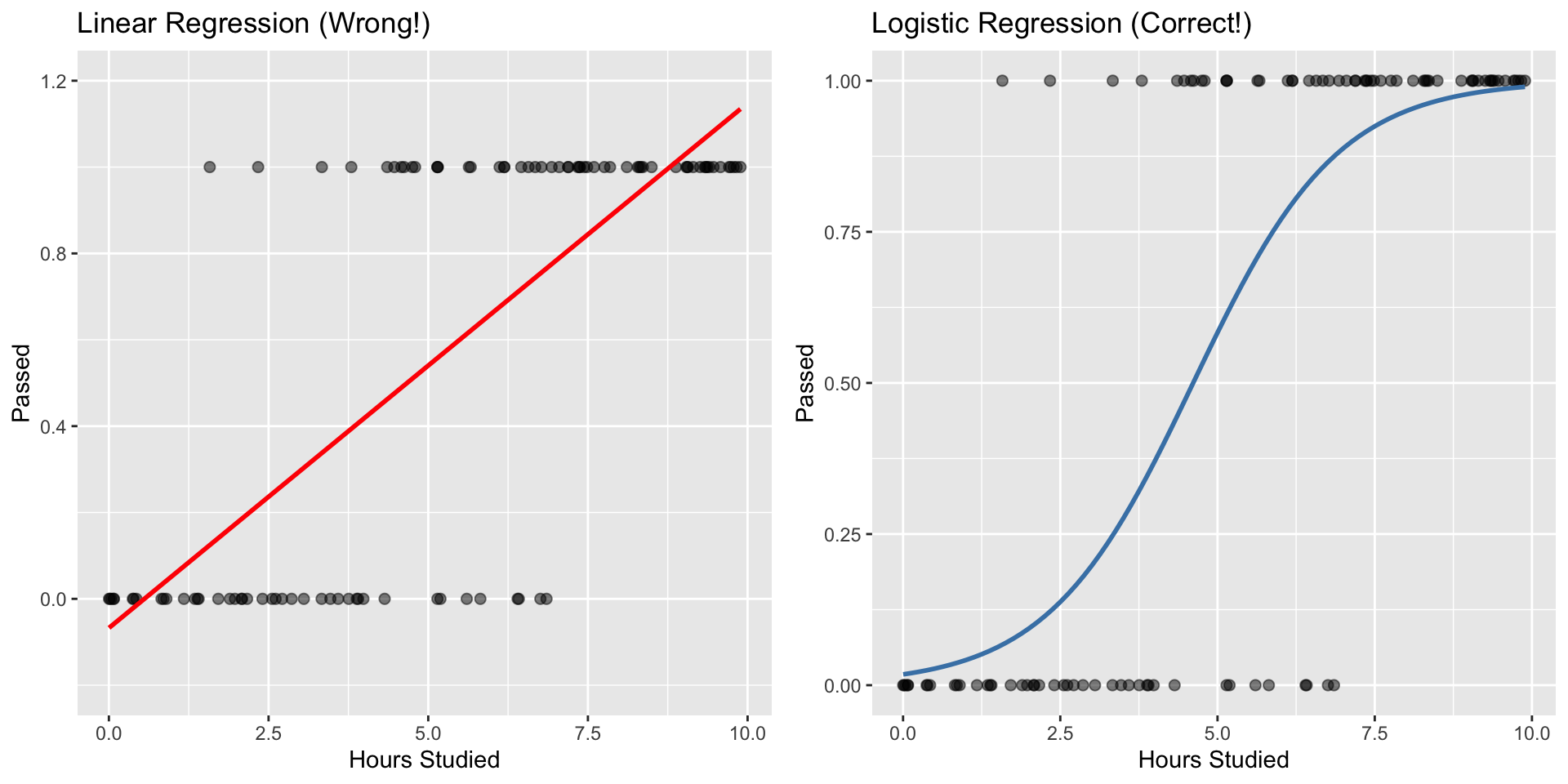
The Fundamental Challenge
This is where logistic regression gets interesting (and complicated):
The model gives us probabilities, but we need to make binary decisions.
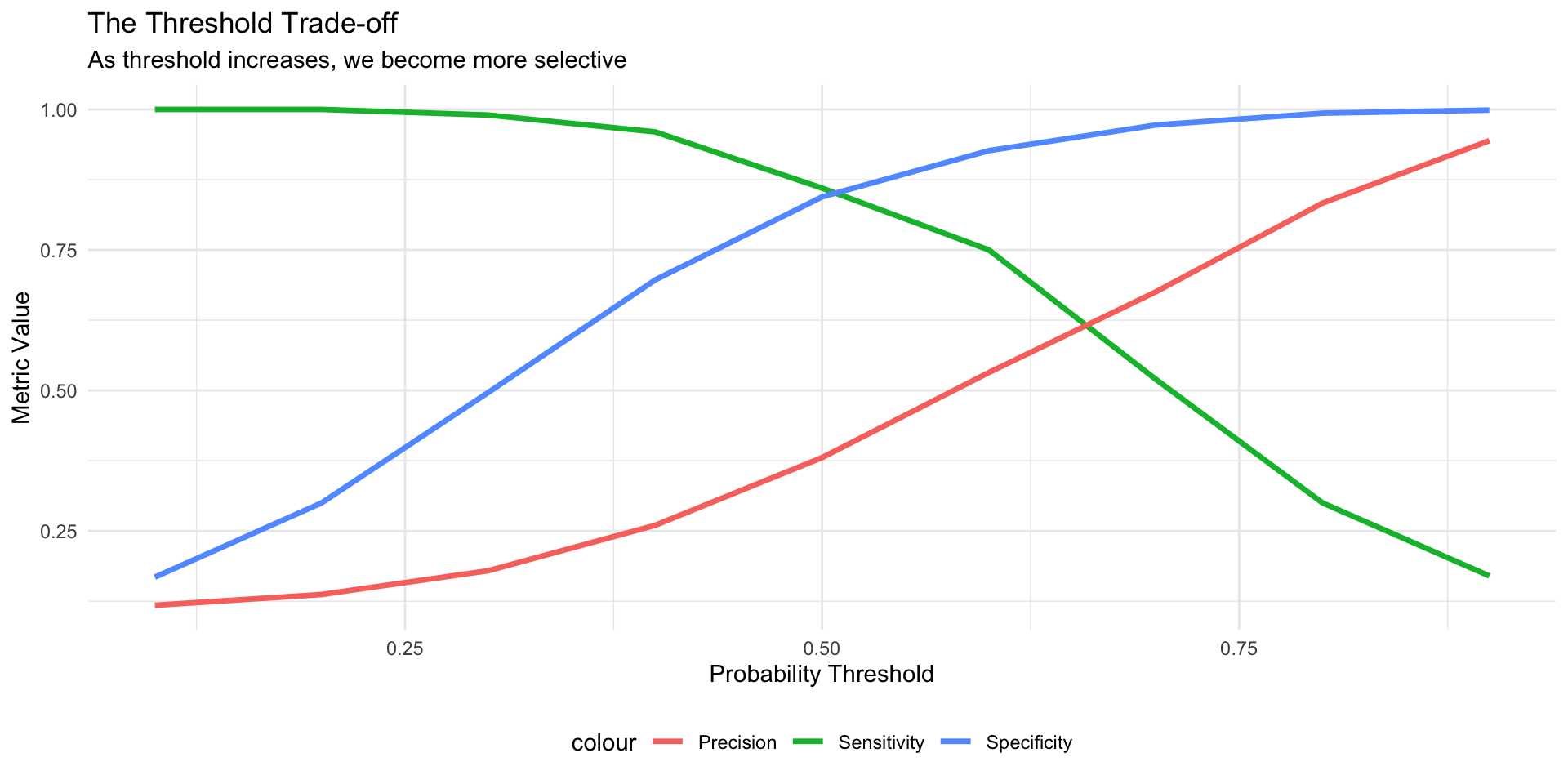
Question: What probability threshold should we use to classify?
Threshold = 0.5? (common default)
Threshold = 0.3? (more aggressive - flag more as spam)
Threshold = 0.7? (more conservative - only flag obvious spam)
The answer depends on:
Cost of false positives (marking legitimate email as spam)
Cost of false negatives (missing actual spam)
These costs are rarely equal!
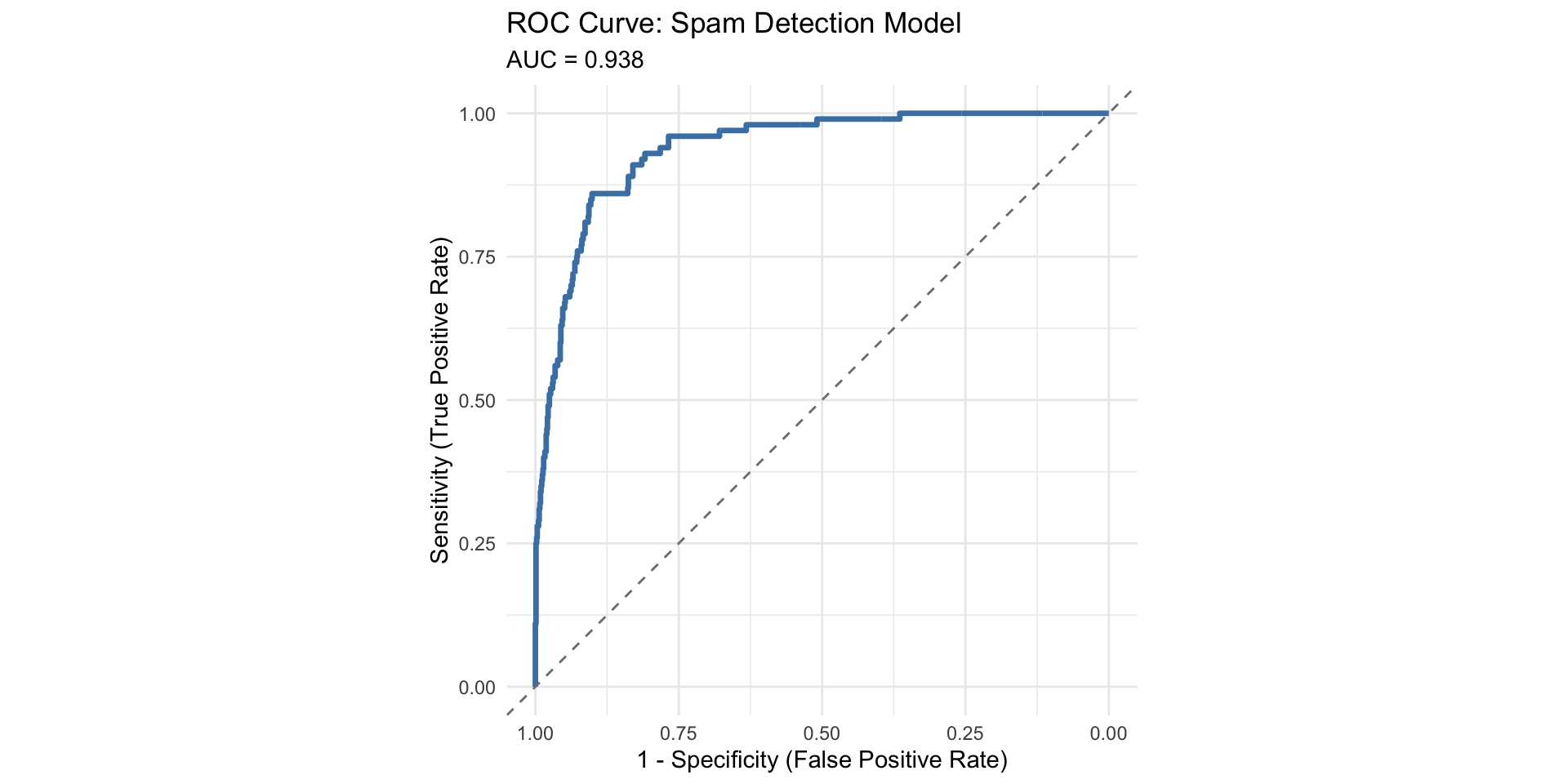
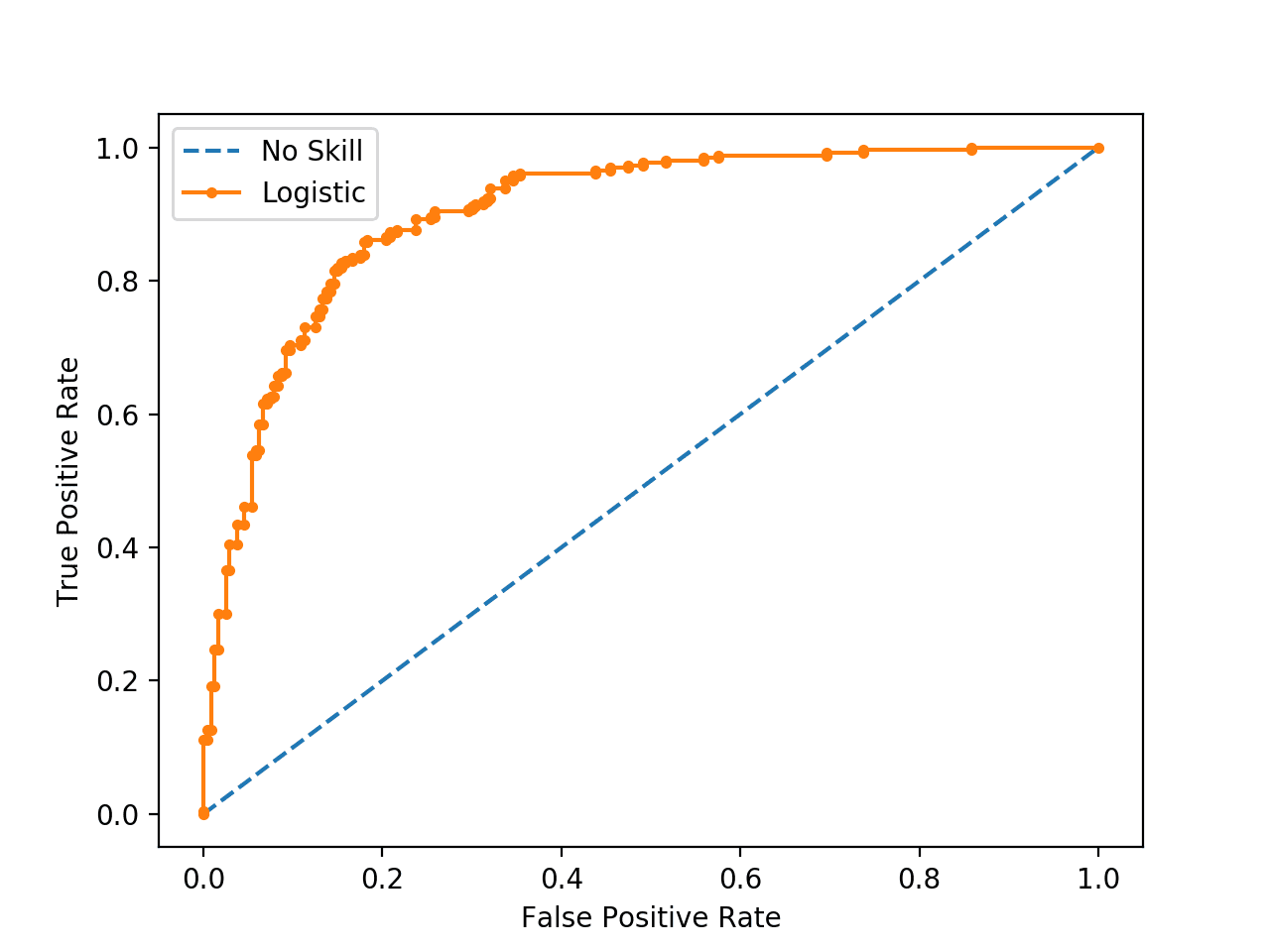
The rest of today: How do we evaluate these predictions and choose thresholds?