Regression Workflow
Building the model:
- Visualize relationships
- Engineer features
- Fit the model
- Evaluate performance (RMSE, R²)
- Check assumptions
Spatial Diagnostics
- Are errors random or clustered?
- Do we predict better in some areas?
- Is there remaining spatial structure?
Spatial Autocorrelation in Errors (i.e. Clustered Errors)
- spatial pattern visible (not random scatter)
- under/over-predict in areas
- model misses something about location
Moran’s I measures Spatial Autocorrelation
Intuition: When I’m above/below average, are my neighbors also above/below average?
Range: -1 to +1
- +1 = Perfect positive correlation (clustering)
- 0 = Random spatial pattern
- -1 = Perfect negative correlation (dispersion)
Defining Neighbors:

Sample Example:
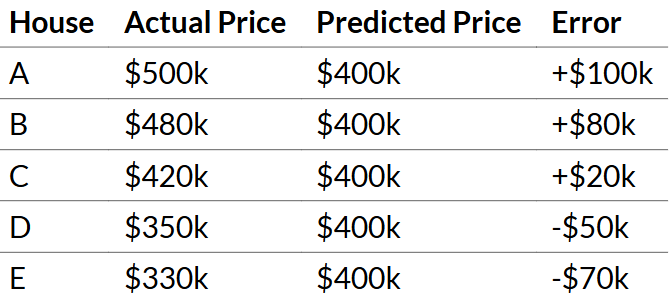
Step 1: Calculate Deviations from Mean
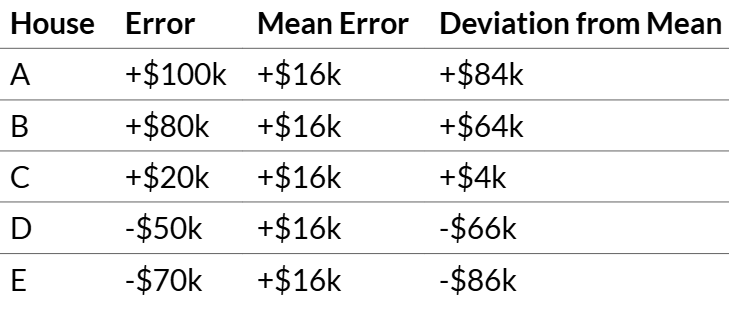
Positive deviation = we over-predicted (actual > predicted)
Negative deviation = we under-predicted (actual < predicted)
Step 2: Multiply Neighbor Pair Deviations

- Lots of positive products → High Moran’s I (clustering)
- Products near zero → Low Moran’s I (random)
- Negative products → Negative Moran’s I (rare with errors)
Step 3: Possible Solutions
If Moran’s I shows clustered errors:
✅ Add more spatial features (different buffers, more amenities)
✅ Try neighborhood fixed effects
✅ Use spatial cross-validation
Issues with Spatial Lag for Prediction:
- Simultaneity Problem (circular logic)
- My price affects neighbors → neighbors affect me
- OLS estimates are biased and inconsistent
- Prediction Paradox (poor generalizability)
- Need neighbors’ prices to predict my price
- But for new developments or future periods, those prices don’t exist yet
- Data Leakage in CV
- Spatial Lag “leaks” information from test set
- Artificially good performance that won’t hold

Key Idea: Match method to purpose:
- inference → spatial lag/error models; prediction → spatial features
- our predicton approach: Instead of modeling dependence in Y (prices), model proximity in X (predictors)